
爬虫的基本流程
网络爬虫不仅是搜索引擎的重要组成部分,而且是目前大数据分析不可缺少的工具。了解爬虫的原理和实现对日常工作或者个人的兴趣爱好有很大的帮助。比如你在百度贴吧里面看到了一遍不错的帖子,这个帖子里面的回复很有价值,你想收藏下来,但是帖子有1000多页,你没办法逐个手动复制;或者你是日系二次元爱好者,喜欢搜集美女图片;或者你对目前的股票、房价的发展趋势想做一些预测;这些需求都可以借助爬虫这个有力的工具得意实现。
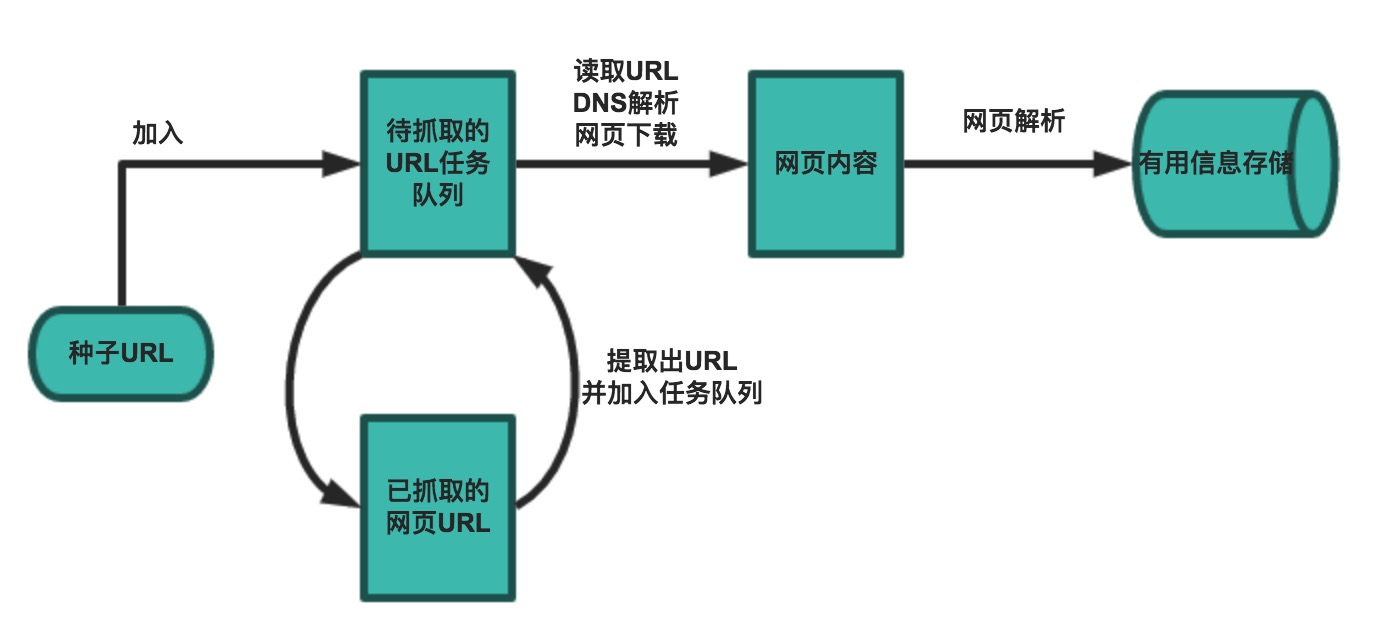
网络爬虫的基本工作流程如下:
- 首先选取一部分精心挑选的种子URL
- 将种子URL加入任务队列
- 从待抓取URL队列中取出待抓取的URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
- 分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
- 解析下载下来的网页,将需要的数据解析出来。
- 数据持久话,保存至数据库中。
爬虫的抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
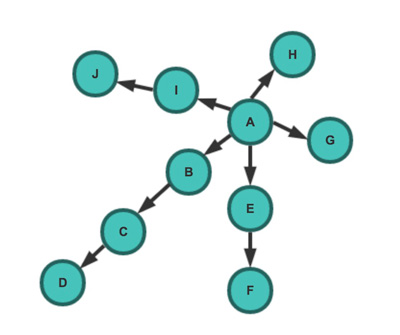
- 深度优先策略(DFS) 深度优先策略是指爬虫从某个URL开始,一个链接一个链接的爬取下去,直到处理完了某个链接所在的所有线路,才切换到其它的线路。 此时抓取顺序为:A -> B -> C -> D -> E -> F -> G -> H -> I -> J
- 广度优先策略(BFS) 宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。 此时抓取顺序为:A -> B -> E -> G -> H -> I -> C -> F -> J -> D
了解了爬虫的工作流程和爬取策略后,就可以动手实现一个爬虫了!




